

DBSCAN vs OPTICS: Building a foundation of high-ROI insights
Our access to data has been likened to our access to oil – abundant, rich, and a symbol of profit and power. But is this really true? At face value, the analogy seems aligned. Even reports show that “new oil” (data) has a greater ROI than “literal oil” in our current market. However, just like ‘real’ oil, while data is inherently valuable, the true scope of its value is brought out in the refinement process. This is where advanced data clusterization techniques come in. It’s the transformational bridge between data’s raw potential and data’s refined insights that drive strategic business operations.
As an R&D partner to our client in the fraud prevention space, advanced clusterization was a solution to make better sense of complex, real-world data. Not only because of the impact of its pre-processing and the result of exceptional pattern detection, but also because of its density-based approach which allows it to better cut through the ‘noise’ of data (i.e. irrelevant information). Collectively, these traits of advanced techniques meant that the data our client was receiving was far more valuable, because it didn’t suffer from artificially imposed parameters or the disproportionate influence of outliers that older techniques failed to filter.
In this article, we’re going to share two specific advanced clusterization techniques (DBSCAN and OPTICS), dig into what strides have been made in this when compared to the older technique of “K-means”, and of course, answer the most popular question right now – “How can this be used to better leverage AI?” Understanding the nuances of each algorithm is crucial for effectively identifying fraud rings and achieving high-ROI insights.
The ultimate amplifier of user understanding
Let’s take our client for example – a leading global fraud prevention solution. They deal with the assessment of complex and highly dimensional data – data that can confirm the honesty or lack of honesty in human behaviour. It’s not a single point of data like a transaction. They have to assess numerous data points simultaneously, from information such as related social accounts and criminal records, to the user’s IP and location match. This, coupled with the more granular behaviour of the user is then translated to better understand the person’s history, patterns, and predictions. Essentially, this means that there is a lot weighing on how the data is categorized. And it could be the difference between blocking a genuinely fraudulent attempt, or blocking a legitimate customer.
Foundational clusterization techniques such as K-means would be limited in the value it could offer here. It makes assumptions on how many sets of clusters there should be, and oversimplifies the data to draw parallels. This means that it would have created generalist insights that would have made it harder for our client to develop fraud prevention rules. K-means’ easy confusion with outliers meant it was more likely to falsely define the characteristics of a ‘normal user’ because it would try to bundle the outlier within a category, which would inevitably contaminate the insights to be gleaned from it.
DBSCAN and Optics however, offer a promising alternative. In the research and development stage, we found that these advanced clusterization techniques were far better at ignoring unusual users that would have little influence on how our client should approach their customers. Instead, both techniques did a far better job of sifting through user behaviour, classifying them according to risk levels, and giving a less distorted representation of user intention. This meant a significant reduction in time needed for a manual review. While both are density-based and excel at identifying clusters of arbitrary shapes and filtering noise (outliers), they differ in their approach to handling varying densities within the data – a crucial factor in detecting sophisticated fraud rings.
What the new clusterization techniques unlock
In an industry where user behaviour is evolving, and user access to new technologies unlocks more creative ways to commit fraud, strong data understanding wasn’t just a priority for our client, it was an absolute necessity.
While this article focuses on the benefits and impacts of these two clusterization techniques (DBSCAN and OPTICS) on the data used in financial services; these techniques could be equally valuable in sorting through user data in industries such as health, law, and education.
This table should give a better understanding of why these new techniques are better suited at dissecting the subtle nuances of user behaviour.
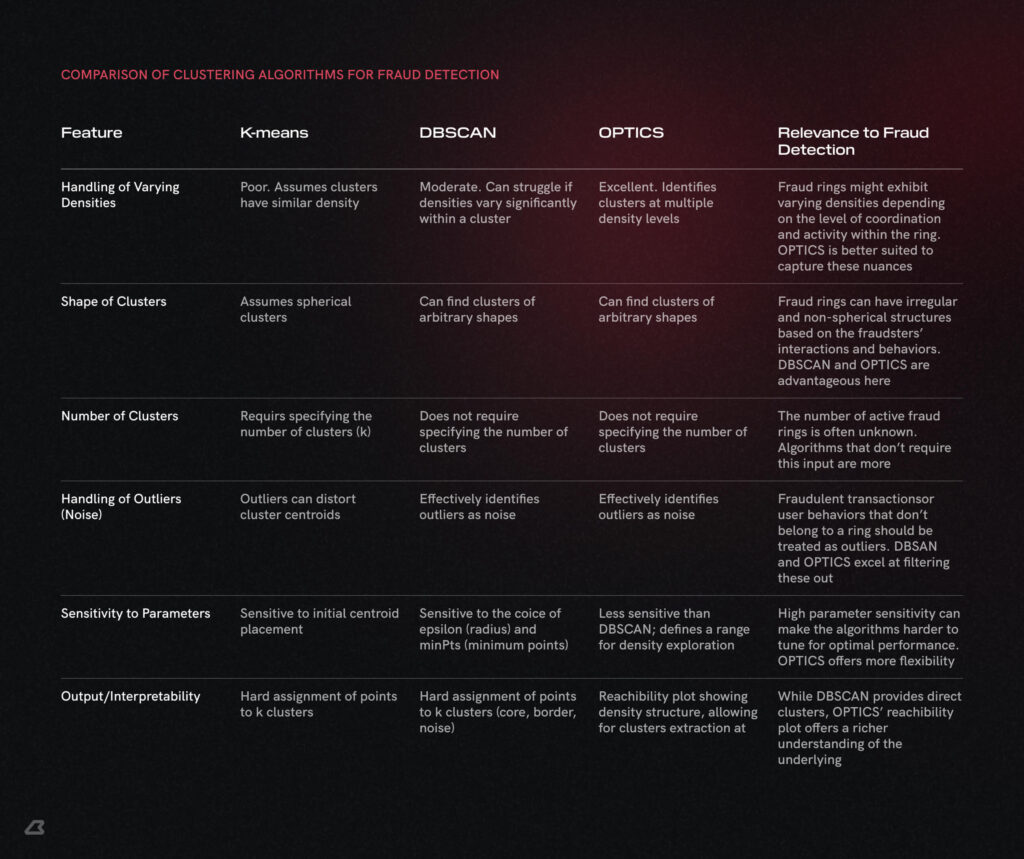
Comparison of K-means, DBSCAN, and OPTICS for Fraud detection across key clustering features
Everyone is into AI right now
“Data is the backbone of AI,” says our CEO, Nick Vasylyna. It would be near impossible to talk about evolutions in data analysis without exploring how this could allow businesses and product-teams to have more tools to leverage when using AI.
Imagine DBSCAN and OPTICS as funnels. By improving the overall quality of data through refining it into richer and more nuanced insights, it is reducing some of the ‘heavy lifting’ of AI. These clusterization techniques act as pre-processors of data. Which results in AI-output that is more personalized, more accurate, and more targeted. We could even argue that these three elements are the most important characteristics of successful strategic interactions with a user-base.
Essentially, new clusterization techniques create far stronger foundations that lead to far smarter AI outputs.
Greater speed and efficiency than its predecessors = a better base for AI to process large data sets required to combat fraud attempts.
Better handling of noise = AI-driven decisions that are based on data that isn’t skewed by imperfect low-relevance user behaviour – a shared strength of both DBSCAN and OPTICS.
Density-based intelligence = AI can ‘piggyback’ off of the real-word contextual understanding of these new techniques, instead of following on from the same assumptive logic of more rudimentary techniques such as K-means. Here lies a key differentiator: DBSCAN identifies clusters based on a global density parameter, which might struggle with datasets where fraud rings have varying densities. OPTICS, by creating a reachability plot, allows for the identification of clusters at different density levels, making it more adept at uncovering hierarchical or multi-density fraud ring structures.
Using data insights to guide corporate strategy
Many of our clients share a common desire – the desire to build a scalable solution that doesn’t add friction to the user experience. And that is why we meticulously fine-tune every aspect of our machine learning solutions, to ensure optimal performance and accuracy.
Data has become an undeniable strategic asset. Many companies that start their journey of data categorization focus on the quantity of data that is being collected. However, they do this without truly understanding that data abundance doesn’t equal data relevance, especially when that data is scattered, unstructured and/ or siloed.
For the specific client that we’ve used as a case study in this article, advanced clusterization is an essential amplifier of their data insights because it allows them to confidently position themselves as a first line of defense against fraud and money laundering. When considering fraud rings, DBSCAN might be sufficient for identifying tightly knit groups with relatively uniform density. However, if the fraud rings exhibit a more complex structure with varying levels of interconnectedness or nested subgroups, OPTICS’ ability to reveal this hierarchy becomes invaluable.
Luckily, these techniques aren’t industry-agnostic. In industries ranging from med-tech, to ed-tech, DBSCAN and OPTICS could be the missing piece in developing market leading solutions, or having a guide for future R&D exploration.
Understanding the nuances of each algorithm allows clients to strategically choose the one that best aligns with their data characteristics and the specific types of insights they aim to uncover. If you would like to explore what high ROI insights your company can uncover, reach out for a consultation.








